
언제 함수화, 클래스화 해야 하는가?
처음부터 모든 것을 염두에 두고 클래스를 만드는 것이 쉽지 않는 경우가 많다
그러므로 코드를 작성하며 유연하게 함수/클래스를 만들어야 한다
그렇다면 언제 함수, 클래스를 만들어야 하는가? 나는 다음 규칙에 따라 함수와 클래스를 만든다
- 동일한 작업을 중복해서 수행한다면 함수로 만든다
- 함수 및 함수의 집합이 상태를 가져야 한다면, 클래스로 만든다
즉, 코드 중복이 있으면 함수로 만들고, 함수가 전역 변수를 이용하거나 함수 간 변수를 공유한다면 클래스로 묶는게 좋다
함수화 : 문자열 정렬 및 생략
아래는 실제 코드를 작성하며 언제 함수, 클래스를 만드는지 과정을 설명한다
문제 확인
1
2
3
4
5
6
# DB에서 리스트 형태로 정보를 가져오는 함수
query = db.select_all("PROGRAMS")
results = query.execute().all()
# 이 위치에 결과를 표의 형태로 출력하는 코드를 추가
첫 두줄의 코드는 이해하지 않아도 된다
위와 같은 파이썬 코드가 있고, 이 터미널에 DB의 정보를 모두 출력하는 코드를 작성해야 한다고 가정하자
1
2
for item in results:
print(item)
단순히 print로 출력을 할 수도 있다
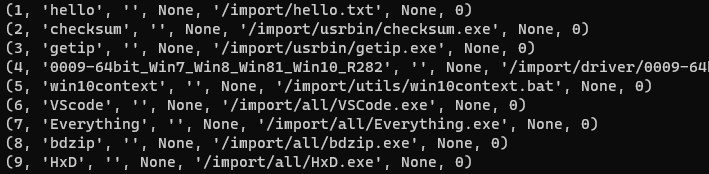
일단 출력은 되지만 원하는 방법은 아니다
표의 형태로 출력하고 싶다
1
2
3
4
5
for item in results:
sys.stdout.write(f"| ")
for value in item:
sys.stdout.write(f"{value} | ")
sys.stdout.write("\n")
| 로 각 정보를 구분하게 하고 다시 출력한다
코드 설명
sys.stdout.write은 표준출력으로 보내는 함수로,print에서 줄바꿈이 되지 않고 몇몇 파라미터를 설정할수 없는 함수로 이해하면 된다""앞에f를 붙여 f-string을 사용하는데, python 3.6 부터 추가된 문자열 포매팅 방식으로 중괄호{}로 변수 및 표현식을 감싸 문자열로 출력할 수 있다
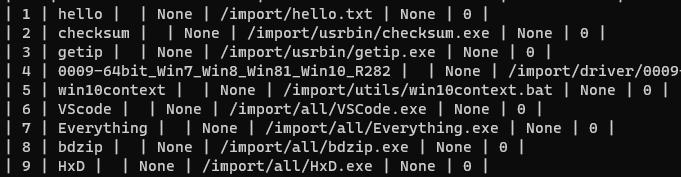
이것도 원하는 결과가 아니다
전혀 정렬되어 있지 않아 보기에 불편하고 예쁘지도 않다
1
2
3
4
5
title1="hi"
title2="abc"
print(f"| {title1:<4} |")
print(f"| {title2:<4} |")

간단한 정렬은 f-string 포매팅의 기능을 통해 쉽게 구현할 수 있다. 중괄호 안의 표현식 오른쪽에 :로 구분하고 가운데 정렬(^) 및 왼쪽 정렬(<)을 할 수 있다
하지만 이 경우는 우리 코드에 적용하기엔 몇가지 문제가 있는데
1
2
3
4
5
6
7
8
title1="ab"
title2="welcome"
desc1="description"
desc2="description"
print(f"| {title1:<4} | {desc1}")
print(f"| {title2:<4} | {desc2}")
print(f"| {title2[:4]:<4} | {desc2}")

첫번째로 지정한 정렬 길이를 벗어나면 그대로 넘어가서 정렬이 흐트러진다
슬라이싱([:])으로 지정한 길이만큼만 보여줄 수도 있지만 뒤가 어색하게 짤리게 된다
뒷부분을 자른다면, ...를 붙여 생략되었다는 것을 표시하고 싶다
1
2
3
4
5
6
7
title1="ab"
title2="안녕"
desc1="description"
desc2="description"
print(f"| {title1:<4} | {desc1}")
print(f"| {title2:<4} | {desc2}")

두번째 문제는 한글, 한자 등은 영어 알파벳과 차지하는 폭이 달라 정렬이 깨지게 된다
한글 1자와 영어 2자가 동일한 폭을 가지지만, f-string 포맷팅에서 정렬 기능은 이를 신경쓰지 않는다
따라서 이 문제를 해결하기 위해선 직접 정렬 기능을 구현해야 한다
정렬 구현
1
2
3
4
5
6
def padleft(text:str, num:int)->str:
length = len(text)
if length < num:
return text + " " * (num-length)
else:
return text
padleft() 함수를 만들고 f-string의 정렬기능과 동일하게 구현했다
1
2
3
4
5
6
7
8
9
def padleft(text:str, num:int)->str:
length = 0
for c in text:
if ord(c) > 0xFF:
length += 2
else:
length += 1
return text + " " * (num-length)
여기서 고쳐야 할 건 한글, 한자와 같은 글자는 길이가 2가 되도록 해야 한다
코드 설명
ord()는 유니코드로 숫자로 변경하는 함수이다- 조건문
ord(c) > 0xFF으로 알파벳 여부를 확인한다- 단순히 아스키코드 범위(0xFF=255) 내에 있다면 길이를 1로, 아니라면 길이를 2로 지정한다
- 다른 유니코드 범위의 길이가 1인 문자는 잘 판정을 못하겠지만 지금은 이 정도로 충분할 것이다
1
2
print(f"| {padleft(title1, 4)} | {desc1}")
print(f"| {padleft(title2, 4)} | {desc2}")

padleft()을 적용했을 때, 한글도 정상적으로 정렬된 것을 확인할 수 있다
코드 분리 및 함수화
1
2
3
4
5
6
7
8
9
10
11
12
def getlength(text):
length = 0
for c in text:
if ord(c) > 0xFF:
length += 2
else:
length += 1
return length
def padleft(text:str, num:int)->str:
length = getlength(text)
return text + " " * (num-length)
왼쪽 정렬 뿐 아니라 가운데, 오른쪽 정렬의 향후 구현이 필요할 수 있다
폭을 고려한 길이를 구하는 코드를 따로 빼서 함수화 한다
함수화
여러 코드가 중복된다면, 그 부분을 따로 빼서 함수로 만든다
다만 코드가 중복되더라도 구현 중 우연히 겹친 것이라면, 섣부른 함수화는 하지 않는다
padleft의 ‘길이를 구하는 코드’는 앞으로 구현할 padmid, padright 등의 함수에서도 사용될 것이므로 함수로 빼는 것이 적절하다
반대로 html을 작성하는 코드에서 동일한 html 코드가 여러번 사용된다고 생각하자
1
2
3
4
5
6
7
contents = "<body>"
contents += "<div></div>" # 중복 코드 1
contents += "<div></div>" # 중복 코드 2
contents += "<div></div>" # 중복 코드 3
contents += "</body>"
위의 div 요소를 생성하는 코드는 세번이나 반복되지만, 이는 우연히 겹친 것이지 기능적으로 동일한 기능을 수행 한 것이 아니기 때문에 굳이 함수로 뺄 이유가 없다
섣불리 함수로 묶었다간 이후 코드를 짜면서 div에 id나 class를 추가하는 등의 작업이 필요하다면 함수 내 조건식을 넣어야 하므로 더 복잡해지며, 다시 함수화를 풀어야 할 수 있다
가운데 정렬 함수 구현
1
2
3
4
5
6
7
8
# import math 필요
def padmid(text:str, num:int)->str:
length = getlength(text)
padding = num-length
left = math.floor(padding/2)
right = math.ceil(padding/2)
return " " * left + text + " " * right
math 라이브러리를 이용해 가운데 정렬을 구현한다
정렬 길이 문제
1
2
3
4
5
6
7
8
9
10
11
name= [
"name",
"test",
"안녕하세요",
"hello world",
]
print(f"| {padleft(name[0], 4)} | description |")
print(f"| {padleft(name[1], 4)} | description |")
print(f"| {padleft(name[2], 4)} | description |")
print(f"| {padleft(name[3], 4)} | description |")

여전히 padleft(), padmid() 함수의 문제가 하나 남아있다
정렬 길이를 벗어난 경우 뒤에 “…“를 붙이고 생략하는 코드를 추가해야 한다
길이 생략 함수
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def getcharlength(c):
if ord(c) > 0xFF:
return 2
else:
return 1
def reduceto(text:str, reduce_to:int):
length = 0
trimed = None
# (1)
for i, c in enumerate(text):
length += getcharlength(c)
if length > reduce_to:
trimed = text[:i+1]
# (2)
if trimed is None:
return text, length
else:
# (3)
for i, c in enumerate(trimed[::-1]):
length -= getcharlength(c)
if length <= reduce_to - 3:
trimed = trimed[:-i-1] + "..."
length += 3
return trimed, length
문자열을 일정 길이 이하로 짜르고 “…” 로 대체하는 함수를 작성한다
이전의 문자열 전체 길이를 구하는 getlength() 함수 대신 문자 하나의 길이를 구하는 코드를 분리해 getcharlength() 함수로 뺀다
코드 설명
- 인자
text는 자를 문자열,reduce_to는 제한할 길이이다
(1)
text문자열의 길이를 확인하며 for 루프를 돌다가 지정한 크기(reduce_to)를 넘어서면 순회한 문자열까지 잘라 trimed 변수에 추가하고, for 루프를 빠져나간다- 이 경우 trimed에는 전체 길이보다 한글자 넘어서는 문자열이 저장된다
- 문자열의 전체 길이가 reduce_to 길이 내라면, 문자열을 모두 순회한 후 trimed를 갱신하지 않고 for 루프를 끝낸다
(2)
- for문에서 trimed를 갱신하지 않았다면(지정한 크기를 넘어서면)
trimed is None조건문이 참이 되어 전체 문자열과 문자열 길이를 튜플로 묶어 리턴한다 - 조건문이 거짓이면 (3)으로 넘어간다
(3)
- trimed를 역순으로 순회하며 문자의 길이를 length에서 빼면서
reduce_to - 3이하인지 확인한다-3을 하는 이유는 문자열의 끝에 “…“를 붙여야 하기 때문이다
reduce_to - 3보다 낮아지면 trimed에서 줄인 만큼의 문자열을 자르고, “…“를 추가하고, length에 +3 하고 문자열과 길이를 튜플로 리턴한다
padleft(), padmid() 코드 수정
1
2
3
4
5
6
7
8
9
10
def padleft(text:str, num:int)->str:
text, length = reduceto(text, num)
return text + " " * (num-length)
def padmid(text:str, num:int)->str:
text, length = reduceto(text, num)
padding = num-length
left = math.floor(padding/2)
right = math.ceil(padding/2)
return " " * left + text + " " * right
이제 padleft(), padright()에서 getlenth() 대신 reduceto()를 사용한다
getlenth() 함수는 더이상 사용하지 않으니 제거해도 된다
1
2
3
4
5
6
7
8
9
10
11
name= [
"name",
"test",
"안녕하세요",
"hello world",
]
print(f"| {padleft(name[0], 5)} | description |")
print(f"| {padleft(name[1], 5)} | description |")
print(f"| {padleft(name[2], 5)} | description |")
print(f"| {padleft(name[3], 5)} | description |")

이제 범위를 벗어난 문자열은 뒷부분을 생략하고 “…“로 표시된다
클래스화 : 테이블로 표시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# DB에서 결과를 가져오는 코드
query = db.select_all("PROGRAMS")
results = query.execute().all()
# 결과를 표시하는 코드
for info in results:
sys.stdout.write(f"| ")
sys.stdout.write(padleft(info[0], 2))
sys.stdout.write(f" | ")
sys.stdout.write(padleft(info[1], 20))
sys.stdout.write(f" | ")
sys.stdout.write(padleft(info[4], 24))
sys.stdout.write(f" | ")
if info[3] is None:
sys.stdout.write(padleft("-", 10))
else:
sys.stdout.write(padleft(info[3], 10))
sys.stdout.write(f" | ")
sys.stdout.write(padleft(info[2][:5], 8))
sys.stdout.write(f" | ")
sys.stdout.write("V" if info[6] else "X")
sys.stdout.write(f" | ")
sys.stdout.write("\n")

이제 padleft(), padmid()를 통해 원하는 정보를 정렬되게 코드를 작성할 수 있다
표처럼 작성했지만, 각 줄이 무엇을 나타내는지 표시하는 header 가 필요하다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 표의 헤더를 출력하는 코드
sys.stdout.write(f"| ")
sys.stdout.write(padmid("No", 2))
sys.stdout.write(f" | ")
sys.stdout.write(padmid("Name", 20))
sys.stdout.write(f" | ")
sys.stdout.write(padmid("Path", 24))
sys.stdout.write(f" | ")
sys.stdout.write(padmid("Date", 10))
sys.stdout.write(f" | ")
sys.stdout.write(padmid("Hash", 8))
sys.stdout.write(f" | ")
sys.stdout.write(padmid("Hidden", 3))
sys.stdout.write(f" | ")
sys.stdout.write("\n")
## 구분선을 출력하는 코드
sys.stdout.write(f"| ")
sys.stdout.write("=" * 2)
sys.stdout.write(f" | ")
sys.stdout.write("=" * 20)
sys.stdout.write(f" | ")
sys.stdout.write("=" * 24)
sys.stdout.write(f" | ")
sys.stdout.write("=" * 10)
sys.stdout.write(f" | ")
sys.stdout.write("=" * 8)
sys.stdout.write(f" | ")
sys.stdout.write("=" * 3)
sys.stdout.write(f" | ")
sys.stdout.write("\n")
## DB 정보를 출력하는 코드
for info in results:
sys.stdout.write(f"| ")
sys.stdout.write(padleft(info[0], 2))
sys.stdout.write(f" | ")
sys.stdout.write(padleft(info[1], 20))
sys.stdout.write(f" | ")
sys.stdout.write(padleft(info[4], 24))
sys.stdout.write(f" | ")
if info[3] is None:
sys.stdout.write(padleft("-", 10))
else:
sys.stdout.write(padleft(info[3], 10))
sys.stdout.write(f" | ")
sys.stdout.write(padleft(info[2][:5], 8))
sys.stdout.write(f" | ")
sys.stdout.write(padmid("V" if info[6] else "X", 3))
sys.stdout.write(f" | ")
sys.stdout.write("\n")
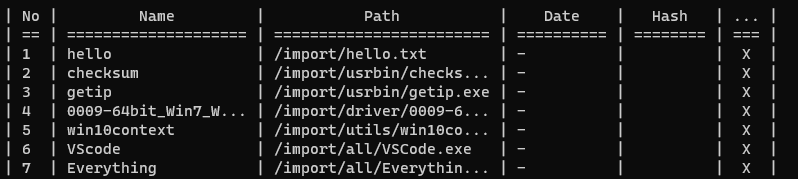
표의 헤더를 추가하는 코드를 작성했다. 다만 Hidden 탭의 최대 문자열 길이는 3인데 제목의 길이가 너무 길어서 짤리므로, 이를 조정해야 할 필요가 있다
또, Path 탭의 정보가 길어서 대부분이 짤리므로 길이를 조절해야 할 필요가 있다
이런 부분을 수정하려면 헤더, 구분선, 정보 쪽 최소 세 부분의 코드를 수정해야 한다. 또, 새로운 정보를 표시하기 위해 탭을 추가하려면 일이 더 커지며 지금 상태로도 코드의 가독성이 심하게 떨어진다
이런 경우 테이블을 출력하는 코드를 따로 분리해 클래스로 만들면 좋을 것이다
클래스화
클래스 생성 및 목적 지정
1
2
class PrintableTable:
pass
테이블을 출력하는 역할을 수행하는 PrintableTable 클래스를 추가한다
이 클래스는 미리 각 탭 별로 미리 패딩 방향, 최대 문자열 길이, 헤더에 표시된 이름을 저장해두고 정보가 든 인자를 받아 출력하도록 할 것이다
1
2
3
4
5
6
7
8
9
10
11
# 클래스 내부 코드
def __init__(self):
self.tableinfo = []
def addhead(self, name:str, *, key:any=None, length:int, padtype:str="<"):
self.tableinfo.append({
"name" : name, # header에 표시될 제목
"length" : length, # 최대 문자 길이
"padtype" : padtype, # 패딩 방향 ('<':왼쪽, '^':중앙)
"key" : key # list형태로 들어오는 index 위치, 또는 dict로 들어오는 데이터의 key를 나타낸다
})
위에서 설명한 목적을 위해, 클래스 내 리스트를 저장하고 addhead() 라는 메서드를 통해 각 탭의 정보를 추가한다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 클래스 내부 코드
def show_head(self):
sys.stdout.write("| ")
for info in self.tableinfo:
name = info["name"]
length = info["length"]
s = self.__padmid(name, length)
sys.stdout.write(s)
sys.stdout.write(" | ")
sys.stdout.write("\n")
def show_line(self):
sys.stdout.write("| ")
for info in self.tableinfo:
length = info["length"]
sys.stdout.write("-"*(length))
sys.stdout.write(" | ")
sys.stdout.write("\n")
1
2
3
4
5
6
7
8
9
10
# 외부 코드
table = PrintableTable()
table.addhead("ID", key=0, length=2)
table.addhead("Name", key=1, length=20)
table.addhead("Path", key=4, length=24)
table.addhead("Date", key=3, length=10)
table.addhead("Hash", key=2, length=8)
table.addhead("Hidden", key=6, length=6, padtype="^")
table.show_head()
table.show_line()

헤더를 출력하는 show_head()와 show_line() 메서드를 작성한다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 클래스 내부 코드
def show(self, item):
sys.stdout.write("| ")
for i, info in enumerate(self.tableinfo):
key = info["key"]
length = info["length"]
padtype = info["padtype"]
value = item[key]
text = ""
match padtype:
case "<":
text = padleft(value, length)
case "^" | _:
text = padmid(value, length)
sys.stdout.write(text)
sys.stdout.write(" | ")
sys.stdout.write("\n")
1
2
3
4
5
6
7
8
9
10
11
12
13
# 외부 코드
table = PrintableTable()
table.addhead("ID", key=0, length=2)
table.addhead("Name", key=1, length=20)
table.addhead("Path", key=4, length=24)
table.addhead("Date", key=3, length=10)
table.addhead("Hash", key=2, length=8)
table.addhead("Hidden", key=6, length=6, padtype="^")
table.show_head()
table.show_line()
for info in results:
table.show(info)
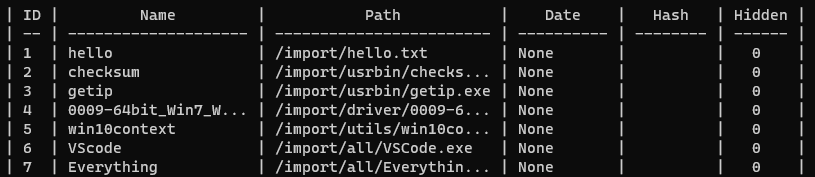
각 정보를 출력하는 show() 메서드를 작성한다
이제 클래스 외부 코드가 간결해진 것을 확인할 수 있다
(추가) 클래스 다듬기
람다를 이용해 정보 가져오기
터미널의 Hidden 탭의 정보가 0으로 표시된다. 이를 이전과 같이 “X”, “V”로 표시하고 싶다
이를 해결하기 위해선, 클래스는 addhead()에서 지정한 key에 정보를 가져오기 때문에 지금 상태로는 미리 인자로 넣는 값을 수정하거나, 클래스의 메소드를 수정해야 한다
클래스의 메서드를 수정하는 편이 더 유연하게 쓸수 있으니 내부 메소드를 수정하도록 한다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 클래스 내부 코드
# func 인자 추가 및 key 인자의 처리 방법 수정
def addhead(self, name:str, *, key:any=None, func:callable=None, length:int, padtype:str="<"):
if key is not None:
if func is not None:
raise "Only one parameter allowed : key and func"
else:
func = lambda x : x[key]
self.tableinfo.append({
"name" : name,
"length" : length,
"padtype" : padtype,
"func" : func
})
def show(self, item):
sys.stdout.write("| ")
for i, info in enumerate(self.tableinfo):
# 이제 key 사용하는 대신 func에 item을 넣어 정보를 가져옴
value = info["func"](item)
length = info["length"]
padtype = info["padtype"]
text = ""
match padtype:
case "<":
text = self.__padleft(value, length)
case "^" | _:
text = self.__padmid(value, length)
sys.stdout.write(text)
sys.stdout.write(" | ")
sys.stdout.write("\n")
addhead() 메서드에 func 인자를 추가한다
여기서 func는 이전의 key를 대체하는 인자로, 람다를 통해 정보를 가져온다
다만, 단순히 key를 집어넣는게 더 간편할 때가 있으므로 key도 유지하고 key와 func를 동시에 쓰지 못하도록 했다
key 인자는 lambda x : x[key] 함수를 func에 넣어 이전과 동일한 동작을 하도록 한다
show() 메서드에선 key를 통해 정보를 가져오는 부분을 func를 호출해 가져오도록 변경했다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 외부 코드
table = PrintableTable()
table.addhead("ID", key=0, length=2)
table.addhead("Name", key=1, length=20)
table.addhead("Path", key=4, length=28)
table.addhead("Date", key=3, length=10)
table.addhead("Hash", key=2, length=8)
# func 인자를 사용하는 코드
table.addhead("Hidden", func=lambda x: "V" if x[6] else "X", length=6, padtype="^")
table.show_head()
table.show_line()
for info in results:
table.show(info)
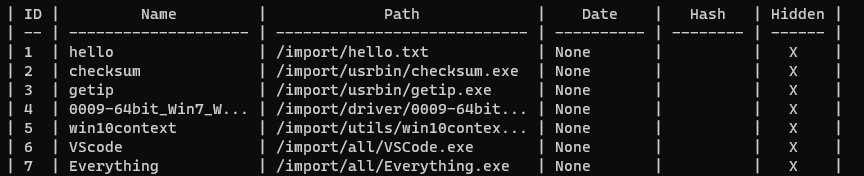
이제
문자열 정렬 함수를 클래스 내부로 이동하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
# 클래스 내부 코드
@classmethod
def __padleft(cls, text, num):
text, length = cls.__text_reduceto(text, num)
pad = num-length
return f"{text}" + " " * pad
@classmethod
def __padmid(cls, text, num):
text, length = cls.__text_reduceto(text, num)
p1, p2 = cls.__numsplit(num-length)
return (" "*p1) + f"{text}" + (" "*p2)
@classmethod
def __text_reduceto(cls, text:str, reduce_to:int):
text = str(text)
length = 0
trimed = None
for i, c in enumerate(text):
length += cls.__charactlen(c)
if length > reduce_to:
trimed = text[:i+1]
if trimed is None:
return text, length
else:
for i, c in enumerate(trimed[::-1]):
length -= cls.__charactlen(c)
if length <= reduce_to - 3:
trimed = trimed[:-i-1] + "..."
length += 3
return trimed, length
@classmethod
def __stractlen(cls, text):
text = str(text)
length = 0
for c in text:
length += cls.__charactlen(c)
@classmethod
def __charactlen(cls, c):
if c == "":
return 0
elif ord(c) < 0xff:
return 1
else:
return 2
@classmethod
def __numsplit(cls, n):
if n <= 0:
return 0, 0
elif n % 2 == 0:
d = int(n/2)
return d, d
else:
d = int((n-1) / 2)
return d, d+1
문자열 정렬 코드는 이제 클래스 내부에서만 사용되므로 클래스 내부로 이동해도 문제가 없다
클래스 내부로 옮긴 함수엔 자신을 가르키는 첫 인자를 추가해 클래스 메서드 문법에 맞게 바꾼다
또, 정렬 관련 함수는 그 자체만으로 작동하므로 @classmethod를 붙여 인스턴스의 상태에 종속적이지 않다는 것을 명시적으로 표시하는 것이 좋아보인다
PrintableTable 클래스 전체 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
class PrintableTable:
def __init__(self):
self.tableinfo = []
def addhead(self, name:str, *, key:any=None, func:callable=None, length:int, padtype:str="<"):
if key is not None:
if func is not None:
raise "Only one parameter allowed : key and func"
else:
func = lambda x : x[key]
self.tableinfo.append({
"name" : name,
"length" : length,
"padtype" : padtype,
"func" : func
})
def show_head(self):
sys.stdout.write("| ")
for info in self.tableinfo:
name = info["name"]
length = info["length"]
s = self.__padmid(name, length)
sys.stdout.write(s)
sys.stdout.write(" | ")
sys.stdout.write("\n")
def show_line(self):
sys.stdout.write("| ")
for info in self.tableinfo:
length = info["length"]
sys.stdout.write("-"*(length))
sys.stdout.write(" | ")
sys.stdout.write("\n")
def show(self, item):
sys.stdout.write("| ")
for i, info in enumerate(self.tableinfo):
value = info["func"](item)
length = info["length"]
padtype = info["padtype"]
text = ""
match padtype:
case "<":
text = self.__padleft(value, length)
case "^" | _:
text = self.__padmid(value, length)
sys.stdout.write(text)
sys.stdout.write(" | ")
sys.stdout.write("\n")
@classmethod
def __padleft(cls, text, num):
text, length = cls.__text_reduceto(text, num)
pad = num-length
return f"{text}" + " " * pad
@classmethod
def __padmid(cls, text, num):
text, length = cls.__text_reduceto(text, num)
p1, p2 = cls.__numsplit(num-length)
return (" "*p1) + f"{text}" + (" "*p2)
@classmethod
def __text_reduceto(cls, text:str, reduce_to:int):
text = str(text)
length = 0
trimed = None
for i, c in enumerate(text):
length += cls.__charactlen(c)
if length > reduce_to:
trimed = text[:i+1]
if trimed is None:
return text, length
else:
for i, c in enumerate(trimed[::-1]):
length -= cls.__charactlen(c)
if length <= reduce_to - 3:
trimed = trimed[:-i-1] + "..."
length += 3
return trimed, length
@classmethod
def __charactlen(cls, c):
if c == "":
return 0
elif ord(c) < 0xff:
return 1
else:
return 2
@classmethod
def __numsplit(cls, n):
if n <= 0:
return 0, 0
elif n % 2 == 0:
d = int(n/2)
return d, d
else:
d = int((n-1) / 2)
return d, d+1